受到左耳朵耗子的影响,我决定沉下心来阅读分布式系统领域的经典文章,今天这篇论文是这个系列的第一篇。
Dynamo能做什么?
Amazon在实践中观察到,它们平台很多服务的数据访问都是简单通过主键进行的,并不要求关系型数据库所提供的复杂查询功能,但对可拓展性和可用性的要求很高,在这种背景下,Dynamo孕育而生。
Dynamo对外提供对单一数据对象的简单读写接口,数据对象由主键唯一标识,不支持跨数据对象的查询或关系操作。 为了实现高可用和可拓展,Dynamo在数据一致性上做了妥协,只保证最终一致性(我感觉好像很少有保障强一致性的服务了)。
Dynamo是怎么做到的?
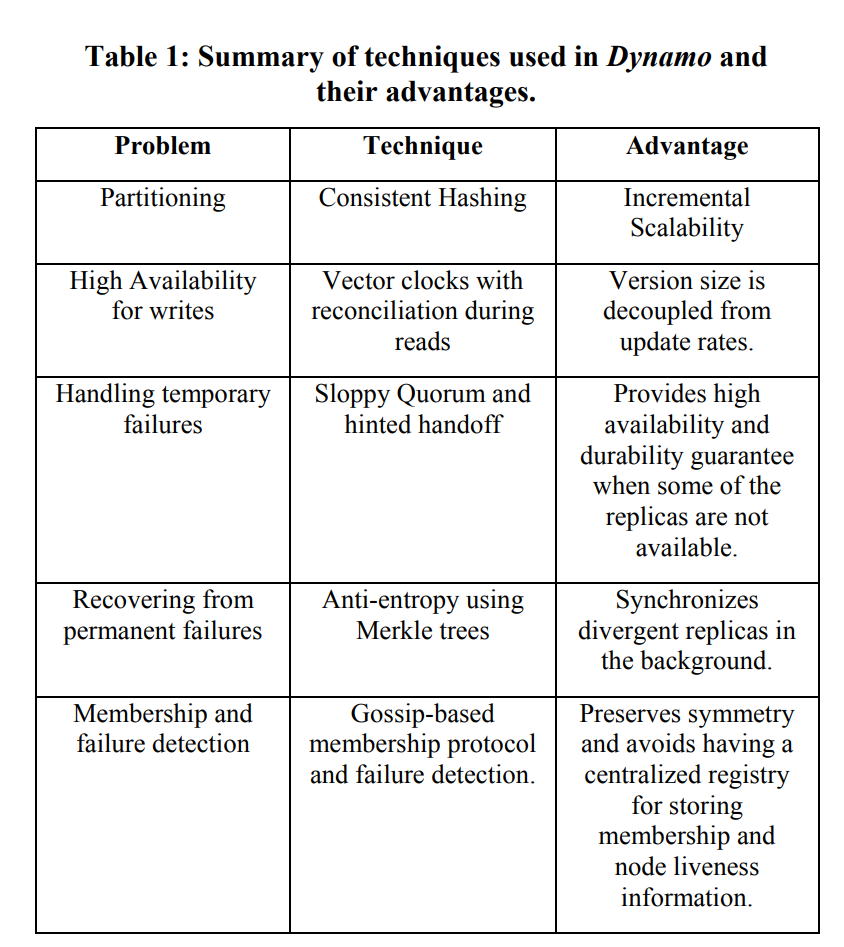
Dynamo通过上图的技术选型实现了其主要特性,接下来我们依次介绍。
对一致性哈希的改进
Dynamo使用一致性哈希算法实现数据分片和可拓展性。
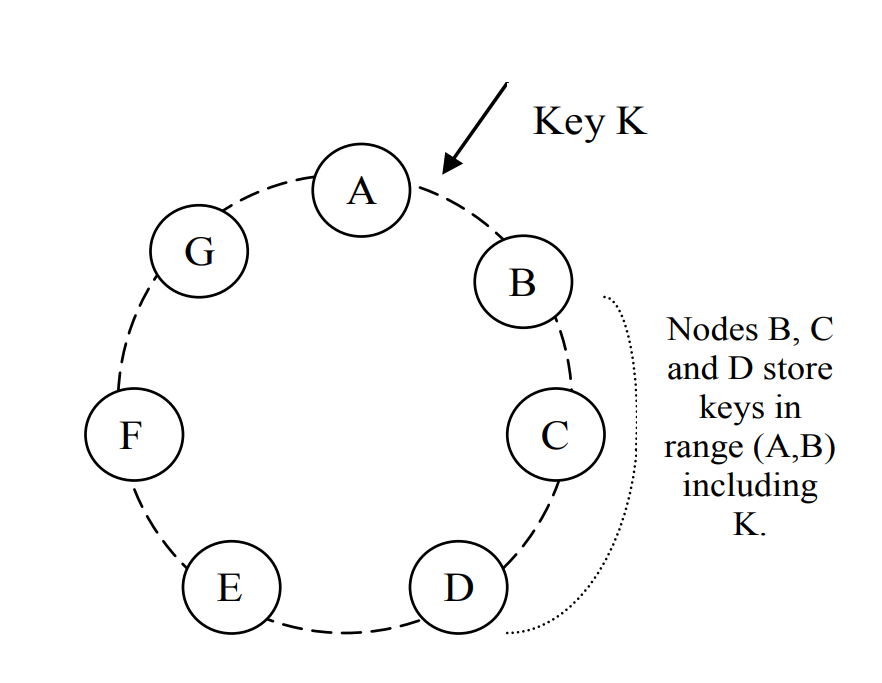
在经典的一致性哈希算法中,数据和存储节点被按照一定规则分配到哈希环的某个位置, 从数据位置出发,顺时针方向找到的第一个存储节点就是数据的存储节点。 按图举例,K落在AB区间,顺时针找到的第一个存储节点B即其目的地。 若出现节点加入或者退出,则只会影响到变动节点前后两个区间的数据分配,对整个集群影响不大。 如,如果在AB区间新增节点C,则AC间的数据转为C负责; 若C退出集群,则B将负责AC间节点。
这种原始方式的问题在于,存储节点不一定有相同的数据负载或访问压力,可能某些热点数据集中在特定区间, 则负责该区间的存储节点自然压力更大,更好的做法是让负载小或能力强的存储节点负责更多的数据, 而这可以通过虚拟节点实现。 虚拟节点的引入使得一个物理存储节点能够在哈希环上对应多个位置,自然其负责的数据量也就更大了。
除此以外,Dynamo会将在N个实例上存储数据,增强高可用和持久化能力。 当数据被分配到一个节点上时,该节点不光自己维护数据,也负责将数据复制到环上后续的N-1个节点中。 前面的图给出的其实是N=3的例子,落在AB区间的数据将由B存储,而B还会将该数据复制到C和D上。
在Dynamo里,当请求涉及到特定key时,每个节点都会针对key值计算一个preference list, 其中包括存储该key数据的物理节点。为了避免节点崩溃,preference list中的节点通常多于N。
使用向量时钟保证数据一致性
为了解决异步读写导致的数据不一致现象,分布式系统通常使用某种类型的逻辑时钟来标定数据版本,例如在 Raft日志复制时,使用Term配合Index来保证日志的强一致性。
Dynamo使用向量时钟来保证读写时数据一致。 向量时钟可以被视为<node, counter>对的列表,对每一个数据对象D,Dynamo都会记录这样的列表。
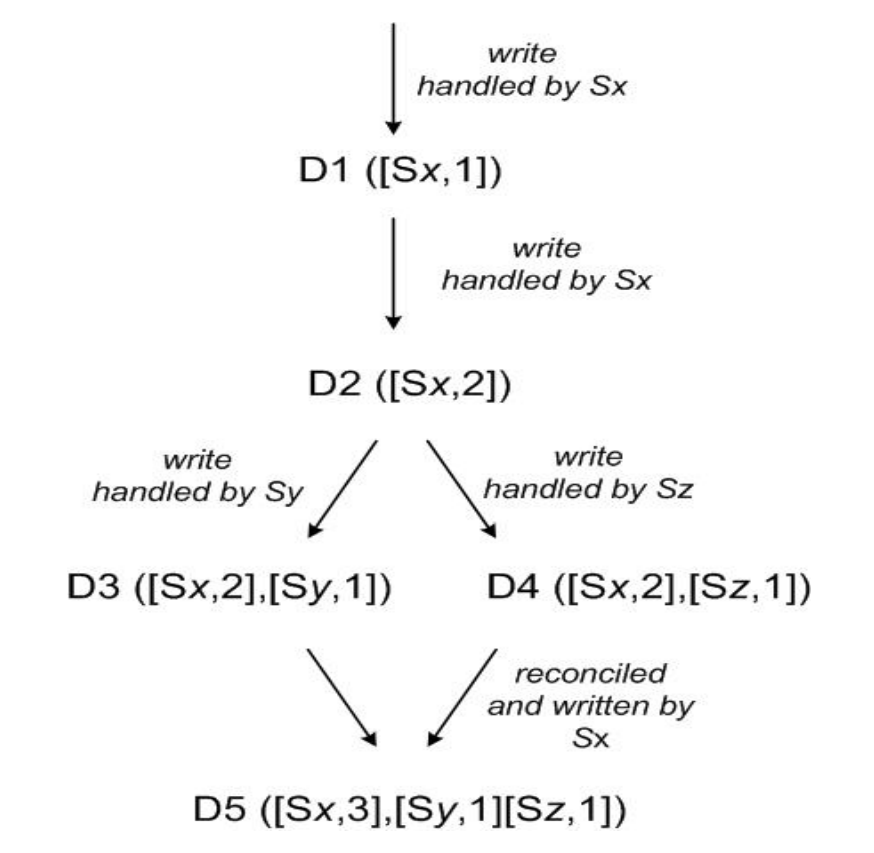
Paper中给出了向量时钟的数据更新示例,假设我们有三台服务器Sx、Sy、Sz。 首先Sx写入数据,此时数据的向量时钟为[<Sx, 1>],再次写入时对应的counter+1。 然后,另外两台服务器分别对数据进行改动,因此向量时钟中出现了新的<node, counter>,对应图中的D3和D4。 Dynamo server和client交互时会传递context信息,其中就包含向量时钟。 设想,某个client已知的版本信息为D3,但下一次读操作时获取到了D4,两者并不能根据版本号自动合并(毕竟是不是所有的node都一一对应,且版本号不存在一边倒的大小关系),client就将根据业务逻辑完成数据合并,并将版本信息更新为D5所示的状态。
向量时钟的潜在问题是时钟大小可能出现爆炸,毕竟大规模的集群可能出现成百上千个节点,要是每个节点都进行写操作的话,<node, counter>列表势必膨胀。paper认为,由于由局部性原理,写操作实际上只会集中在某些节点上,时钟大小的膨胀是可以接受的。Dynamo同时记录了每次更新的时间戳,并按照一定阈值淘汰过于陈旧的版本信息对,但显然,这种历史信息的清理必将影响到后续版本更新。例如,假设<node, 3>在一次操作中被清理,但client侧还保留着该信息,下一次server的更新为<node, 1>,此时client再和这台server交互,就不能根据counter来判断数据版本了。原paper仅仅简单提了一句该问题,但并没有提供有效的解决方案。总而言之,这种方案就像是git一样,是一种乐观锁, 将数据冲突合并的责任转让给业务逻辑,简化了Dynamo的设计。
使用Quorum和接力机制进行数据恢复
所谓Quorum,即系统针对某次数据更新操作达成共识的最少票数, 例如在Raft里,我们需要超过半数节点都同意某次读或写操作(写入日志), leader才能认为操作成功,并返回给client。
Dynamo使用R和W两个参数定义读写两类操作的Quorum。 不论是哪种操作,收到请求的节点都先计算向量时钟,然后在对应的preference list中给前N个节点发送请求, 当达到对应操作的Quorum时,方才视为操作成功。 对于读操作,如果获得了多个版本的数据,则将汇总返回给client,由client合并再更新。 当R或W设置合理时,即使系统出现了局部崩溃,也可以对外提供服务。
Dynamo同时使用一种名为Hinted Handoff的接力机制来实现数据的临时托管。 回到之前的一致性哈希图,假设A出现故障,那么之前A负责的数据请求将暂时由D接管, 以保持相同的高可用性(否则GA区间的数据就只有两份备份了)。 D将在一个独立的数据库中记录接管的数据,其元数据中包含原主信息。 一旦检测到A恢复,D就按照原主信息将数据转移回A,转移成功后删除这部分本地数据。
Merkle tree:应对永久数据损失
数据恢复过程中,托管节点也可能出现不可用的情况,此时就需要快速检测节点间数据的不一致性, 仅仅同步不一致的那部分数据,Dynamo使用Merkle tree实现这个目的。
Merkle tree其实是一种节点带哈希值的二叉树,每个节点的哈希值为左右子树哈希值合并后的哈希结果。 如果两棵树在某一个节点上哈希值一致,那么该节点下的两棵子树就是一致的,不用再进行比较了。 尽管在树构建的过程中多次使用了哈希算法,但是在进行对比时却省了很大功夫: 只需要按照树的遍历找到不一致的节点就可以了,不必对每个部分依次比较,这也有助于减少数据传输量。 比特币其实也使用该算法进行区块链校验,而在Dynamo里,每个节点对它所负责的哈希环区域都维护一棵Merkle tree。
成员变更和崩溃检测
当有节点加入或离开集群时,其他节点需要能够感知到这种成员变动, Dynamo使用gossip协议完成这个功能。
成员变更通常是由管理员向节点发送请求指定的,接收请求的节点会将变更历史(内容和时间)写入一个持久化仓库。 在gossip协议的每一轮(每秒),节点都会随机选择一个其他节点对齐变更历史,从而实现成员变动的同步。
这种设计不能应对短时间多个新加节点互相感知的需求(它们只能先和集群中已有节点同步变更历史,才能知道对方的存在),因此,Dynamo设置了种子节点的角色,确保每个节点都实现知晓该节点的存在。它就像是一个节点注册中心一样。
除此以外,gossip协议还使节点能够及时感知到部分成员(或自身)的崩溃,以便及时调整自己接收或转发client请求的行为,因为gossip message其实起到了心跳检测的作用。
由于后续我计划精读gossip论文,这里就不介绍这种协议的细节了。
总结
为了实现一个高可用的kv存储,Dynamo主要做了这样几件事:
- 将数据冲突合并的逻辑移交给业务方实现,自身只负责数据存储部分。
- 使用逻辑时钟来做数据版本验证。
- 支持可调整的Quorum机制,通过放开R和W的设置,上游业务可以根据自身需要在一致性和可用性之间实现权衡。
从我目前的经验来看,逻辑时钟、Quorum等技巧已经成了后端分布式服务中的标配,这篇文章很好地总结了这些常用的点。 需要注意的是,Dynamo用“实际情况”这个理由规避了对向量时钟大小、Merkle tree构建等内容的讨论, 对此读者还要保持一定的质疑。