Major Probelm
地址匹配应该算是短文本匹配的一个子类,其表层问题在于同样的一个地址元素,表达方式可以是多种多样的,字符相似度不等于语义相似度。

基于规则的匹配方法
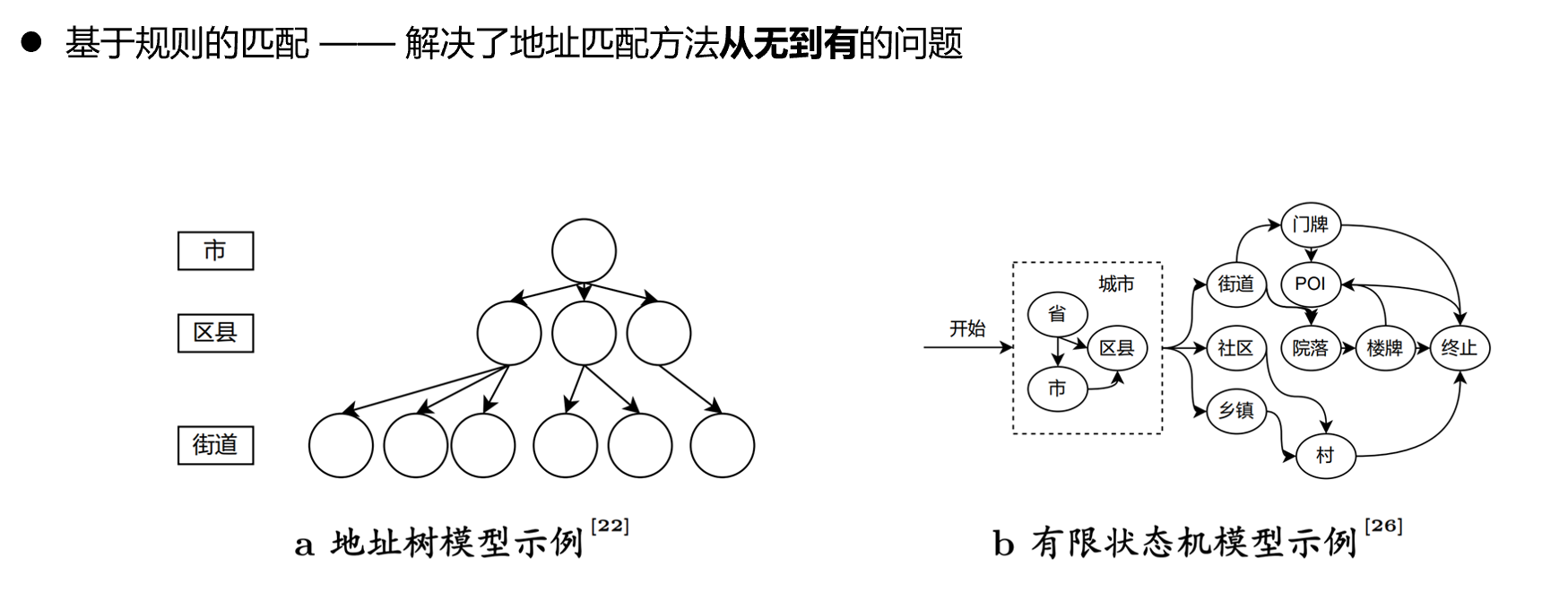
由于无法直接通过字符串相似度(编辑距离之类的算法)来简单得到地址相似度,学者开始研究如何把一句完整的地址文本拆分成有地理意义的地址元素。对于地址元素,则可以通过规则库的方式来定义相等关系。例如,尽管“武大”和“珞珈山人民公园”在字符上风马牛不相及,但是如果能把这两个地址元素识别出来,再强行定义一条两者相等的规则,这两条地址就能够被判定为匹配。
另外,人们基于朴素的观察,认为地址可以认为是具有地理约束关系的地址元素的文本集合,这些关系包括包含、相邻等。 如果能够按照这样的关系顺序进行识别,只要上层的地址元素不匹配,就不必再进行下层地址元素的讨论了。 由此,学者开始着手构建所谓的“标准地址模型”,希望能够设计出这样一种涵盖了大多数情况的规则库。
这种做法的问题有二:
如何把地址元素从地址文本中精确的拆分出来?
这个问题类似于NLP中的分词问题,“南京市长江大桥”到底要被拆分成“南京市”、“长江”、“大桥”,还是“南京市长”、“江大桥”?
另外,即使能够实现地址元素的拆分,地址元素的等级又该如何确定?首先,“标准地址模型”中可能没有定义一些具有地域特色的等级,如胡同、弄、里等;其次,一些地址元素本身不具有特指意义,必须依托父元素而存在,如“某某小区A单元”中的“A单元”。
这两种情况将增加地址元素等级和分词算法的复杂度。
如何维护地址元素间的状态转移规则?
上图展示了规则方法对地址元素转移的规则呈现,然而,现实生活中总会出现未曾定义过的状态转移形式,比如出现了相同等级的地址元素、出现了地址元素的回环等。一旦出现了类似的情况,这类方法就会失效,除非长久地投入人力来维护这个日益冗杂的规则库。如果把千奇百怪的非标准地址也纳入规则库,那么“标准地址模型”也就不再标准了。
基于表示学习的匹配方法
表示学习的匹配方法大概是前几年深度学习热引起的,这类方法的结构大致是首先将地址文本拆分成token,再将token转换为编码,使用一些时髦的特征增强手段将两个句向量转换成一个特征表示,通过MLP将这个特征表示计算为匹配概率。
事实上,一旦把字符转换成向量,地址匹配的问题就已经解决了大部分了,如果只用向量化算法配合静态的余弦相似度的话,也足以应对大多数情况。其余的部分大都用于处理短文本匹配领域的极端情况,而地址文本特征比通用短文本简单太多,只是名词性短语的组合罢了,以致于相关研究的各项指标都能轻易拉到0.98左右,从应用的角度来看已经失去了意义。
这类方法的弊端是对数据量的要求越来越大,研究人员不光需要收集海量的地址数据,还要把这些地址数据配成标注好的地址对格式,且要确保匹配与不匹配的比例相近。考虑到地址数据本来就因为敏感性和安全性难以获取,这类方法的可用性大打折扣。
未来的可能趋势
首先,大模型对中文地址匹配的冲击难以忽视,但这并非给领域内的小型专家模型下了死刑。 第一,对于有实际业务需求的小企业,大模型的微调成本比目前的领域方法要高。 第二,大模型似乎还不能解决小样本训练问题。 第三,用通用的大模型驱动小的专家模型是一个未来方向。
另外,该领域对数据的需求愈加明显,但领域内并未出现可以拿来比较的公共数据集,导致这个领域的各个方法基本上都是自说自话,缺少公信力。因此未来可能研究的有两个方向:(1)提供公共脱敏数据集加速研究交流;(2)研究小样本的地址匹配方法,减少数据依赖。