Raft算法实现
6.5840 / 6.824(分布式系统)Lab 2,实现Raft算法。
NOTE:本文为 6.824(分布式系统)Lab 2 的回顾,实验要求见这里。因为要遵守课程的 Collaboration Policy,所以本文不会分享任何实现细节的代码(可能还是会有一些逻辑性的简单代码帮助阐明思路)。
Lab 2 要求我们用 Go 语言实现 Raft 算法。客户将与 Raft 集群中的 Leader 节点通信,其操作会被记录到 Leader 节点的 Log 中。集群中的若干 Raft 节点可以通过 RPC 通信,以确保 Leader 节点的 Log 能够复制到集群中的大部分节点中,从而实现容错。
课程提供了不少学习资料:
- Raft 论文:这篇论文对算法中关键 API 进行了十分详尽的描述,尤其是 Figure 2 和 Figure 13,在编码时应该反复琢磨。事实上,大多数编码的 bug 都是因为没有完全按照论文的思路来。
- Raft 动画:这个动画可以帮助我们理解 Raft 算法的执行过程,我在实现 Leader Election 的时候反复参考了这个动画。
- Students' Guide to Raft:这是 TA 写的一篇博客,对我们在做 Lab 时可能踩的坑都做了说明。
你可能和我一样,这么多资料读下来直接被 overwhelmed 了,anyway,最根本的一点是,要对原论文的思路保持敬畏,不要有意无意地对算法细节进行 “优化”。
下面我们从 4 个子 Lab 的顺序回顾一下实现过程。
Part 2A: leader election
在一个 Raft 集群中,只有 Leader 节点能接收客户端的请求,并向集群中的其他节点复制 Log。当 Leader 节点宕机后,集群中的其他节点需要能意识到这一点,并选举出新的 Leader 节点。由于之前的 Leader 能够将 Log 复制到大多数节点中,所以新的 Leader 节点保有之前的 Log,从外界看,集群的状态是连续的。
我们首先看看 Figure 2 中对 Raft 节点状态的描述:

我们当前只关注和选举有关的状态:
currentTerm:当前任期(我们后面还是称 Term),Raft 节点通过 Term 判断整个集群的状态,Term 越大则代表该节点处于更新的状态。其他节点如果在通信过程中遇到了 Term 更新的节点,则必须无条件接收新的 Term。同时,只有 Term 最大的节点有资格被选举为 Leader。votedFor:在每一轮选举中,一个节点只能投出一票,当它遇到了下一个向它争取选票的节点时,如果它和候选者 Term 相等,则首先检查这个变量看是否已经投票,如果没有,则投给这个节点。(如果 Term 不相等,则根据两者 Term 大小,如果候选者 Term 更大,则更新自己的 Term,然后投票给候选者;反之忽视这次通信,在回复中写入自己的 Term)phase:这个变量不在论文的描述中,但是在实现中很有用。
Raft 节点的状态转移
Raft 节点在全过程中会在如下几个状态切换:
const (
FOLLOWER = iota
CANDIDATE
LEADER
)原论文中有这样一个状态转移图,同时前面提到的动画对这个过程的描述也很生动。
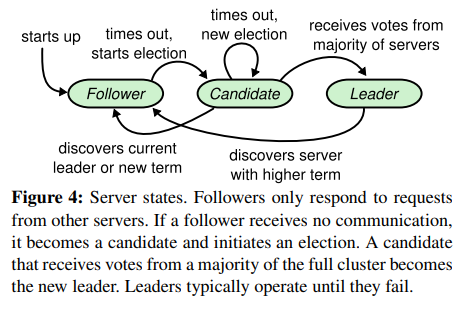
- 在初始状态下,所有节点都是 FOLLOWER,FOLLOWER 状态的节点希望能每隔一段时间就收到 LEADER 的 AppendEntries 请求,即心跳包。
- 如果在这段时间没有收到心跳包,则认为 LEADER 宕机,它将自己的 Term 加 1,变成 CANDIDATE 状态,向其它节点发送 RequestVote 请求,争取选票。
- 其它的节点(不论状态),在收到 RequestVote 后,如果自己的 Term 更大,则拒绝投票,并将自己的 Term 写入回复,否则首先检查自己的 votedFor,如果没有投票,则投给候选者,并将自己的 Term 写入回复。
- 如果候选者收到了大多数节点的投票,则成为 LEADER,否则继续保持 CANDIDATE 状态,直到下一轮选举。
- 如果一个节点在收到的消息中发现,对方有更大的 Term,则它无条件变为 FOLLOWER,同时更新自己的 Term。
在实现过程中,每个节点需要保留一个 electionTimeout 状态,每当 FOLLOWER 收到心跳包时,就重置这个状态,如果在这个状态内没有收到心跳包,则变为 CANDIDATE。同理,CANDIDATE 在超时之后也将 Term 加 1,并发起一轮新的选举。LEADER 则不用管这个状态。
总结起来,在选举过程中有两个时间变量需要考虑:
electionTimeout:FOLLOWER 和 CANDIDATE 的超时时间,如果在这个时间内没有收到心跳包,则变为 CANDIDATE,发起新的选举。heartbeatInterval:LEADER 的心跳包发送间隔。
在实现过程中,我每隔 50ms 检查一次当前状态,如果是 LEADER,就向其它节点发送心跳包,如果是 FOLLOWER 或 CANDIDATE,则检查 electionTimeout ,如果超时,则变为 CANDIDATE,发起新的选举。
心跳机制
我们首先关注已经存在一个 LEADER,并且不会出现 LEADER 宕机的情况,这样我们就只需要实现 AppendEntries:

该函数有两重作用:
- 作为心跳包,用于维持 LEADER 的地位。
- 用于复制 Log,当客户端向 LEADER 发送请求时,LEADER 会将请求写入自己的 Log,并向集群中的其他节点发送 AppendEntries 请求,要求它们也将这条 Log 写入自己的 Log 中。
为了不让问题复杂化,此时我们只关心第一个作用。我在 Raft 节点启动时,设置一个独立的 goroutine 来处理心跳包的发送和 electionTimeout 的检查,这样就不会影响到其他的函数调用。
func (rf *Raft) ticker() {
for !rf.killed {
time.Sleep(50 * time.Millisecond)
rf.mu.Lock()
if rf.phase == LEADER {
rf.replicateLog(true)
}
if time.Now().After(rf.electionTimeout) {
rf.startElection()
}
rf.mu.Unlock()
}
}这里的 replicateLog 函数实际上综合了前面所提的两个作用,参数表明此时是发送心跳包还是复制 Log。对于 LEADER 而言,在其视角中,其它的 Raft 节点都是 FOLLOWER,因此它只需要遍历 rf.peers ,向每个节点发送 AppendEntries 请求即可。在这个过程中,LEADER 会将心跳包所需的参数填入请求中,Figure 2 中其它的参数可以简单设置零值,此时还不用管,注意发送 RPC 请求应该是一个并发的过程,每一次发送都在一个新的 goroutine 中进行。完成发送之后,LEADER 会检查每个节点的回复,这个阶段只需要像所有节点一样,检查 Term 的大小即可:
- 回复中的 Term 更大:LEADER 变为 FOLLOWER,更新自己的 Term,并且重新设置
electionTimeout。 - 回复中的 Term 更小:忽略这个回复。
- 两者相等:这是一次正常的收发。
对于 FOLLOWER 而言,它同样进行检查 Term 的过程,如果是合法的 TERM(不考虑选举,则始终相等),就重新设置 electionTimeout 即可。
实现选举过程
现在我们增加难度,考虑 LEADER 可能宕机的情况:

如果一个 FOLLOWER 在 electionTimeout 内没有收到心跳包,则认为 LEADER 宕机,它将自己的 Term 加 1,变成 CANDIDATE 状态,,重新设置 electionTimeout ,并向其它节点发送 RequestVote 请求,争取选票。
当对方回复后,我们需要检查两件事:
- Term 是否合法:这和前面的 Term 检查逻辑一致。
- 此时该节点是否仍然是 CANDIDATE:有可能集群中多个节点同时发起选举,而该节点收到了 Term 更大的 CANDIDATE 的 RequestVote,自动变回了 FOLLOWER,此时它应该忽略自己之前争取的投票结果,
我使用一个 voteCounter 变量来记录得票数,此外,为了确保从 CANDIDATE 到 LEADER 的转变只发生一次(超过半数即转变,但是超过半数后可能还会收到新的赞成票),我使用了 sync.Once 。
func (rf *Raft) startElection() {
...
var becomeLeader sync.Once
voteCounter := 1 // vote for itself
for i := range rf.peers {
if i == rf.me {
continue
}
go rf.candidateRequestVote(i, &args, &voteCounter, &becomeLeader)
}
}
func (rf *Raft) candidateRequestVote(server int, args *RequestVoteArgs, voteCounter *int, becomeLeader *sync.Once) {
...
if reply.VoteGranted {
*voteCounter++
if *voteCounter > len(rf.peers)/2 {
becomeLeader.Do(func() {
... // become LEADER
})
}
}
}另外, electionTimeout 需要用随机数重置,这么做是为了防止多个节点同时发起选举,均未获得过半选票,又同时等待相同时间再选举的活锁现象。
Part 2B: log
在这一部分我们需要实现 Log 的复制,这也是 Raft 的核心功能。LEADER 需要保存用户操作,并将其复制给其他节点。当大部分节点都复制了这条 Log 后,LEADER 才能将其应用到状态机中,这样才能保证集群中的所有节点都有相同的状态。在一些场景中,LEADER 可能由于网络原因暂时失联,但是仍然可以保存用户操作,当它重新连接到集群,需要能在不丢失数据的情况下被重新选举为 LEADER,并将这些操作复制给其他节点。这意味着我们需要在 Part 2A 的选举功能上额外考虑用户操作的时效性。
在该阶段,用户操作日志可以直接保存到一个 Log 数组中,需要注意的是论文中 log 数组的索引从一开始,在编程时需要对数组索引进行转换。
在 Lab 中,用户通过 Start 函数向 Raft 节点发送请求,大致逻辑如下:
- 如果当前节点不是 LEADER,则返回 false。
- 初始化 Log,将其加入到 Log 数组中。
- LEADER 尝试复制 Log,与此同时向客户端返回预期的 Log 索引。
复制 Log 实际上使用的是前面提到的 replicateLog 函数,编码的时候我们很容易想要将心跳包的发送和 Log 的复制分开,但是这样会加重编码负担,而且在后面心跳包中也会检测 Log 的复制情况,两者的逻辑大致相似,不如直接写到一起。
每个 Log 包含以下信息:
type Log struct {
Command interface{}
Term int
Index int
}Command 是用户操作, Term 是该 Log 所在的 Term, Index 是该 Log 在 Log 数组中的索引。Raft 使用 Term 和 Index 来标识一个 Log,Term 可以用来检测 Log 是否连续(想象一下如果一个节点在中间很多 Term 中都没有 Log,可能是因为网络原因导致它有很长时间脱离集群,这个时候需要从它最早的没有冲突的 Log 位置开始复制),Index 用来标识 Log 在数组中的位置,此时的实现可能是简单的索引值加 1,但是后面当我们引入 Log Compaction 后,Log 的索引将会重写。
区分 commit 和 apply
我们回头看下 Raft 节点需要保存的状态:
此时我们需要弄清楚 commitIndex 和 lastApplied 的区别,或者 commit 和 apply 的区别,我在最开始做 Lab 时也对此感到疑惑,但是实际上:
- commit 代表一个当前节点已经记录的 Log。
- apply 代表一个当前节点已经应用到状态机的 Log。
当 LEADER 发现大多数节点都已经 commit 了某个 Log,则可以将其 apply 到状态机中。在 Lab 的实现中,apply 的 Log 会被放入一个 applyCh 通道中通知上层应用,这是通过一个条件变量实现的。
func (rf *Raft) apply() {
rf.applyCond.Broadcast()
}
func (rf *Raft) applier() {
rf.mu.Lock()
defer rf.mu.Unlock()
for !rf.killed() {
if rf.commitIndex > rf.lastApplied && rf.lastLogIndex() > rf.lastApplied {
... // write applyCh
} else {
rf.applyCond.Wait()
}
}
}复制日志
LEADER 通过 nextIndex 和 matchIndex 来记录其他节点的复制情况, nextIndex 代表下一个需要复制的 Log 的索引, matchIndex 代表已经复制的 Log 的索引。两者在每次选出新 LEADER 后重新初始化。
LEADER 将根据 nextIndex 向 FOLLOWER 发送 log,如果正常返回,则将更新 nextIndex 和 matchIndex ,否则将 nextIndex 减一,重新发送。LEADER 会不断重复发送,直到 FOLLOWER 接收到 Log。每次 log 复制完成后,LEADER 将检查 matchIndex ,如果大多数节点的 matchIndex 都大于 commitIndex ,则将 commitIndex 更新为 matchIndex 中的最小值,并且将该 Log 应用到状态机中。
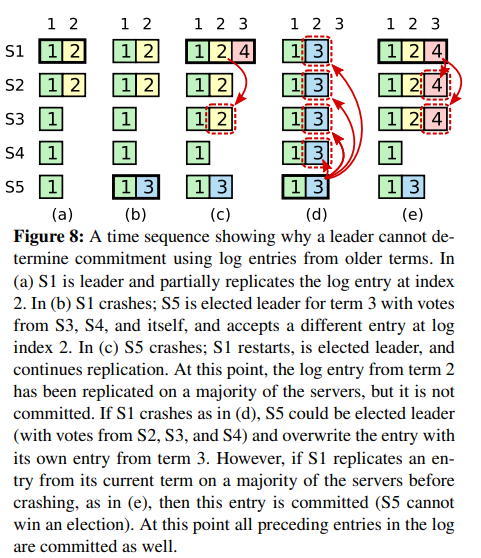
可见, matchIndex 代表和 LEADER 中 log 一致的最新 log 索引, nextIndex 代表下一个要发送的 log 位置。另外,在检查 matchIndex 时,还需要限定 matchIndex 的 Term 必须和当前 Term 一致,这是为了防止在选举过程中,新的 LEADER 将旧的 Log 应用到状态机中,见 Figure 8,即当前任期的 LEADER 无法确定之前的 log 是否成功复制到了大多数节点。
Part 2C: persistence
这部分主要实现 Raft 节点状态持久化,使得节点重启后也能够恢复到之前的状态。这部分在编码上难度不大,只需要利用在 persost 函数和 readPersist 函数中利用 Lab 特供的 gob 库进行编码解码即可。参与编码解码的数据为之前状态图中的持久状态,每次状态改变时即调用 persist 函数存档,当一个 Raft 节点重启时,将在 Make 函数中调用 readPersist 函数恢复状态。
Part 2C 还额外要求对日志复制进行优化,相关内容在原论文中的表述为:
If desired, the protocol can be optimized to reduce the number of rejected AppendEntries RPCs. For example, when rejecting an AppendEntries request, the follower can include the term of the conflicting entry and the first index it stores for that term. With this information, the leader can decrement nextIndex to bypass all of the conflicting entries in that term; one AppendEntries RPC will be required for each term with conflicting entries, rather than one RPC per entry. In practice, we doubt this optimization is necessary, since failures happen infrequently and it is unlikely that there will be many inconsistent entries.
这其实是说之前发现冲突时,LEADER 会将 nextIndex 减一,即每次退回一步重新尝试发送 log,但是这样做的效率很低,可能要回退多次才能到达两个节点一致的日志位置,因此不如让 FOLLOWER 返回两者第一次发生冲突的位置,LEADER 直接从这个位置开始发送即可。
Part 2D: log compaction
一个长时间运行的 Raft 服务可能包括大量的 log 数据,将这些数据全部放在内存中某个数组里显然是不现实的,因此需要对 log 进行压缩,即将一些旧的 log 持久化,这样 log 数组就可以删除这些 log。另外,LEADER 还必须将保存的这部分快照发送给 FOLLOWER,如果 FOLLOWER 落后太多,这样还能加速 FOLLOWER 的同步过程。为了实现这个功能,我们需要在每个 Raft 节点中加入 lastSnapshotIndex 和 lastSnapshotTerm 状态,用于记录当前快照中的最新 log 信息,方便在发送快照时进行判断。
修改 log 数组结构
可以预见,一旦我们删除 log 数组中较旧的一部分元素,就会破坏利用 index 定位 log 的机制,我的想法是用一个 offset 值记录数组中第一个 log 在整个逻辑 log 数组中的位置,之后利用 index-offset 定位 log。这样,当我们删除 log 数组中的一部分时,只需要更新 offset 即可,而不需要对整个数组进行移动。除此以外,还可以给新的结构增加一些工具性的函数,比如获取最后一个 log 元素的 Term 或者 Index,删除某个位置之前的所有 log 等。
完成设计之后我们需要仔细查看之前的代码,用新的结构替换原来的 log 数组。
快照发送
Lab 提供了 Snapshot 接口供应用层调用,也就是说,将何时压缩日志的选择权交给了用户,我们因此只需要关注如何实现快照发送即可。

论文中考虑的是快照容量很大,需要切片分块发送的场景,因此需要 offset 和 done 两个参数来提示 FOLLOWER 当前接收进度。Lab 中只要求我们一次将快照发送完毕,因此不需要做上述考虑。
当 LEADER 发送 AppendEntries 请求复制日志时,它首先判断 nextIndex 和 lastSnapshotIndex 的大小关系,如果将要发送的 log 在快照之前,说明 FOLLOWER 落痕太多,则这一轮发送改为发送 InstallSnapshot 请求(也可以实现为发送快照之后紧接着发送一次快照之后的日志),下次则进入正常的日志复制流程。收到应答之后仍然像正常的日志复制一样检查 Term 合法性,然后更新 nextIndex 和 matchIndex 。
FOLLOWER 在收到快照后同样进行合法性检查,然后根据内存中的数组和快照中保存的数组的重叠情况,对内存中数组进行裁剪即可。此外,Lab 要求我们在收到快照后,向应用层返回一个快照版本的 ApplySmg 。