切片KV存储服务构建
6.5840 / 6.824(分布式系统)Lab 4,在KV存储的基础上添加数据分片,分片迁移等功能。
NOTE:本文为 6.824(分布式系统)Lab 4 的回顾,实验要求见这里。因为要遵守课程的 Collaboration Policy,所以本文不会分享任何实现细节的代码(可能还是会有一些逻辑性的简单代码帮助阐明思路)。
我们在 Lab 3 中基于 Raft 算法实现了简单的分布式 KV 存储系统,服务器维护一个统一的 map,以存储 KV,并支持快照存储数据库状态。但是在实际项目里,服务器可能无法承载过量数据,我们自然想要将数据分配到不同的子集群上,当子集群出于某些原因需要暂时下线时,我们还需要做好分片迁移工作,这意味着我们需要另一个服务器(或者集群,这样容错更强)负责配置数据的分配,其地位相当于 MapReduce 的 Coordinator。
服务架构
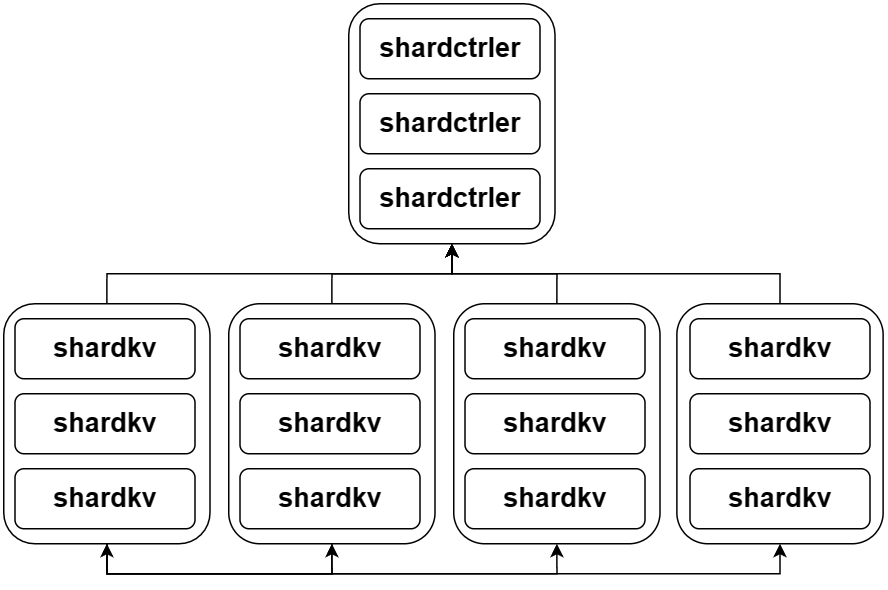
上图中的 shardctrler 和 shardkv 都是基于 Raft 的集群,前者负责维护一个数据分片配置文件,后者将定期从 shardctrler 中 fetch 配置文件,并根据最新配置向兄弟集群请求数据分片。
shardctrler
shardctrler 支持四种 RPC 接口:
Join:一个新的子集群需要接入整个集群。Leave:一个子集群要离开集群。Move:将一个分片从 A 子集群迁移到 B 子集群中。Query:子集群 LEADER 或者用户查询指定版本的数据分片配置情况。
每当有子集群调用 Join 或者 Leave 时, shardctrler 将自动修改当前配置情况,更新配置文件后再返回 RPC。
关于自动配置,我采用的是尽量在每个子集群平均分配分片,并且尽量减少分片迁移的次数,我想这部分策略应该也可以让用户配置。
配置的结构大致如下:
type Config struct {
Num int
Shards [NShards]int
Groups map[int][]string
}该结构体记录了版本号、数据切片的分配情况(分片 id -> 集群 id)和集群中其它成员信息(集群 id -> 主机名),用于互相传递消息。
每当 Config 更新时,版本号就会递增,以便子集群判断是否要进行数据分片迁移。
shardkv
shardkv 的大部分逻辑和 Lab 3 别无二致,只是之前存储所有的数据,现在只需要存储一个数据分片。用户在进行数据库相关操作时,也会向 shardctrl 查询分片配置情况,然后自行计算数据对应分片,向负责的子集群 LEADER 发送 RPC。
真正复杂的地方在于,如何实现配置的更新和数据迁移。
首先看配置更新,服务器有一个独立的 goroutine 周期性访问 shardctrler 调用 Query RPC,但是每次只会请求下一个版本的 Config,这样可以保证整个大集群能够渐进式地往最新版本迁移,否则一旦有某个集群意外离开大集群,同时没有将自身的数据分片迁移,那么所有的集群将无法按照配置迁移其他数据。
我是用拉取的方式来实现分片迁移,但推方式似乎也没有任何问题,为了保证高可用性,一旦服务器不再对外提供某个分片的服务,就会自行进行清理。
上述两种行为也是通过 goroutine 对现有数据分片状态进行周期性扫描来实现的,结合前面的周期性获取下一版本 Config,服务器一共有三个守护 goroutine:
query:向shardctrler周期性请求下一版本 Config,如果请求成功,则开始分片迁移工作。puller:周期性检查切片状态,如果发现需要拉取的分片,根据上一版本 Config 的信息寻找前主人集群,拉取分片。eraser:周期性检查切片状态,如果发现需要清理的分片,根据最新协议询问新主人是否得到了该分片,然后进行清理。
为了代码的简洁,我们也可以使用一个 updater 函数来封装周期性执行函数的逻辑,使前面三个函数之需要考虑自身逻辑。
可以看到, puller 和 eraser 其实都是以切片状态驱动的,有点像是一个状态机。我定义的切片状态如下:
type ShardState int
const (
Serving ShardState = iota
Pulling
Pulled
Removing
)Serving:本集群在最新版本 Config 中提供该分片服务,且已经拿到该分片,正在服务。Pulling:本集群在最新版本 Config 中提供该分片服务,但尚未拉取到该分片,正在拉取过程中。Pulled:本集群在最新版本 Config 中不再提供该分片服务,即被拉取的一方。Removing:本集群在最新版本 Config 中提供该分片服务,且已经获取到该分片,需要其原主人进行分片清理。
我们假设在初始状态,每个子集群都已经拿到了它应该存储的数据切片,在下一个版本的 Config 中,切片分配存在变化。
首先,服务器向 shardctrler 请求下一版本 Config,拿到之后向自己集群同步 Reconfiguration 操作。在该操作中,服务器将已有的 Config 放到 preConfig 中,以便后续数据迁移时使用,然后根据两个版本 Config 的区别,寻找如下两种情况:
- 新 Config 中需要新增的数据分片,标记为
Pulling。 - 新 Config 中删除了的数据分片,标记为
Pulled。
我们的 puller 协程发现有数据分片为 Pulling 状态,即本集群应该提供该分片的服务,但是还没有拉取到该分片,此时参考 preConfig 中的信息,找到该分片的原主人,拉取分片数据,如果成功,则向子集群同步 INSERT_SHARD 操作。
我们的 eraser 协程遍历数据分片后发现,有分片处于 Removing 状态,因此首先确认对方已经删除该分片,然后同步调整我方集群的分片状态为 Serving 。
上述两个步骤是在 RPC 发送方的角度描述的,对于 RPC 接收方,不论收到的是什么请求,首先对比两边的 Config 版本(对方的 Config 会写在请求参数里),只有两边 Config 相同,才往下执行。
对于数据拉取的请求,我们同时对分片数据和操作历史进行深拷贝,然后发送给对方,发送操作历史是为了方便对方忽略已经处理过的请求,因为可能存在用户在切换了目标分片服务器之后,重新发送冗余请求的可能。
对于分片擦除的请求,我方检查分片状态,如果是 Pulled ,说明状态正常,可以清理该分片,否则向对方报错。
总结来看,分片迁移过程中,拉取一方的数据状态变化为: Pulling -> Removing -> Serving ,而被拉取一方则是: Serving -> Pulled -> Serving 。我这里同时用 Serving 标识正在服务状态和已经删除后的状态,因为用户在判断目标子集群时总是通过 Config 得到的,不会被干扰,对一个服务器来说,则可利用 Serving 状态和 Config 信息共同判断自己是否提供某个数据分片的服务。