OS:虚拟化、并发和持久性
本文并非单纯的操作系统导论的读后感或者读书笔记,而是我目前对操作系统的理解的总结,以输出的方式内省学习效果,或许也能当作复习大纲使用。
最近读完了操作系统导论,是我目前读过的逻辑最清晰的操作系统教程。他把操作系统分成虚拟化、并发和持久性三个部分来介绍,辅之以分布式系统的介绍。下面以这本书为纲目,梳理操作系统的基础知识,形成一篇类似于 Journey to the Net 的 blog。
TL; DR
虚拟化
OS 通过资源虚拟化的方式达到两种目的:
- 让系统更易于使用:应用开发者不再需要将考虑和物理资源的交互,比如控制磁盘读写、抢占 CPU 等,基本上要做的事情就变成了:我需要打开某某文件、我需要并发地运行某些过程。
- 保护物理资源不受损害:OS 确保自己对物理资源的管理和使用是绝对安全的,上层应用只能使用标准库来间接操作物理资源或设备,这种隔离能够避免恶意软件破坏计算机。
后面又出现了将应用运行环境虚拟化的 VM 和 container 技术,它们使构建分布式应用更加轻松,这虽然与 OS 的主题无关,但是虚拟化的思路却是一脉相承的。
虚拟化 CPU —— 进程
进程与程序的关系类似于 goroutine 与其中调用的函数的关系,用进程控制块(process control block,PCB)来描述,PCB 包含程序在运行时可以读写的内容:
- 进程标识符(PID):唯一标识一个进程。
- 用户标识符(UID):进程所属的用户。
- 进程优先级。
- 内存指针:程序代码和进程相关数据的指针,和其他进程共享内存的指针。
- I/O 状态:比如进程打开的文件列表。
- 程序计数器(Program Counter, PC):存放程序下一步要访问的指令位置。
- 寄存器状态。
......
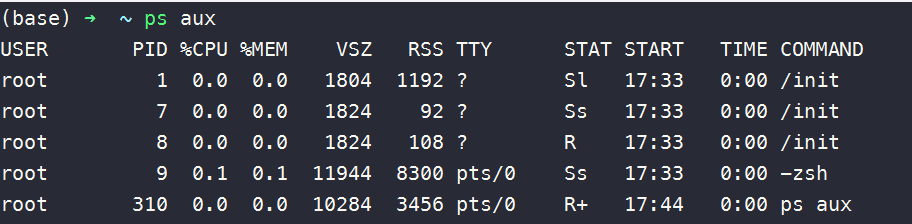
可以使用 ps 输出进程相关的信息,比如我这台 Windows 用 wsl 安装了 Arch Linux 环境,在刚刚启动时的输出结果是这样的:
进程状态
下面这张图来自维基百科:
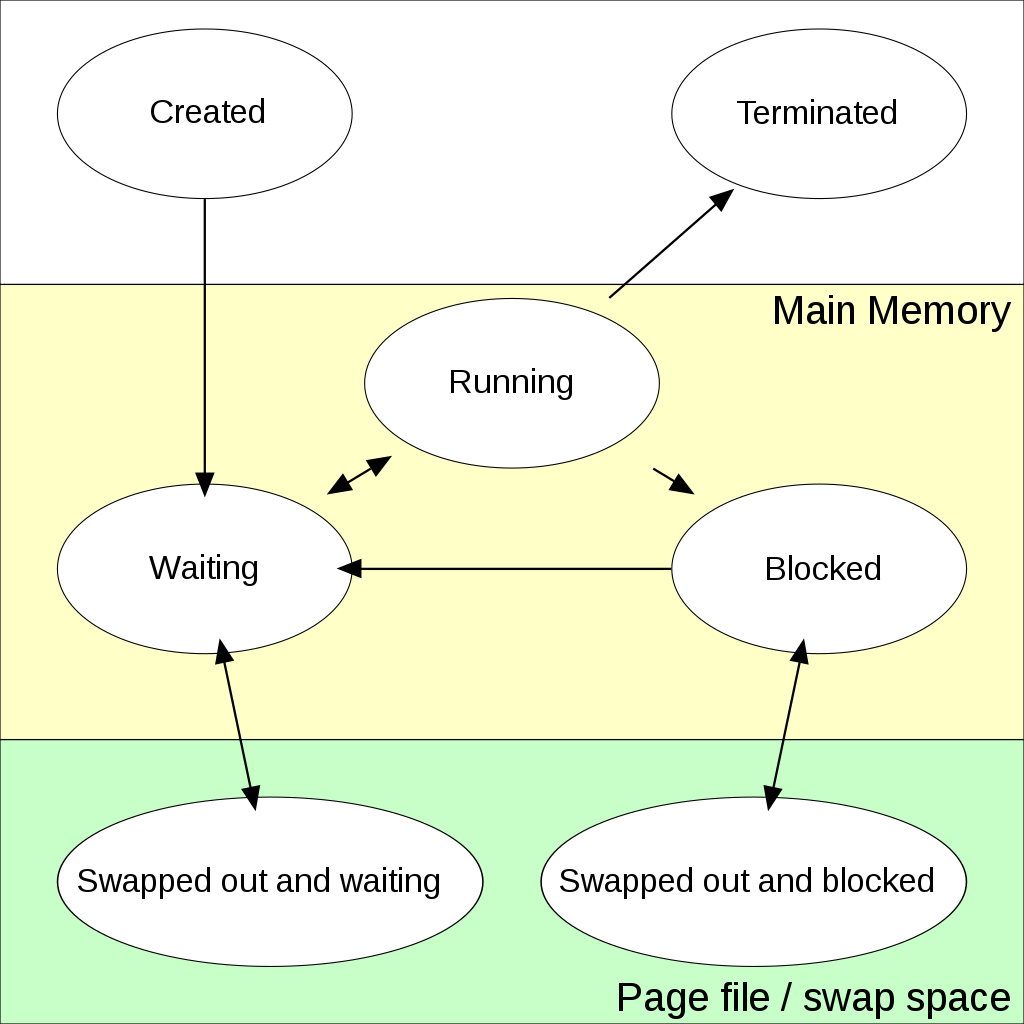
总的来说,一个进程从生到死的状态大概包括:
- 创建:OS 将代码和静态数据加载到内存,并为程序的运行时栈(程序在其中存放局部变量、函数参数和返回地址)和堆(程序可以在这里动态请求内存空间)分配内存,为程序打开标准输入输出和错误的文件描述符 FD。
- 运行:进程占用 CPU,按照 PC 的信息一步步更新寄存器执行任务。
- 阻塞:进程因为要等待某项条件才能继续运行,比如等待用户输入或者 IO 操作。
- 就绪:进程满足运行条件,但 OS 出于种种原因(硬件中断、进程调度、系统资源不足等)并没有运行该进程。
图中还提到了 swap 机制中的两种状态,简而言之,当内存不足时,OS 可以将进程 swap 到磁盘中,释放内存空间给其他进程使用,后面内存虚拟化部分会涉及到。
进程调度算法
我们用周转时间和响应时间来衡量调度策略的优劣:
设计调度算法的难点在于,OS 无法预知他要处理的任务的具体情况。常被提到的调度算法包括先进先出(FIFO 或 FCFS)、最短任务优先(Shortest Job First, SJF)、最短完成时间优先(Shortest Time-to-Completion First,STCF)、时间片轮转(Round-Robin,RR)、多级反馈队列(Muti-Level Feedback Queue)和比例份额(proportional-share)等。
FIFO 和 SJF 过于简单,由于队列中靠后的任务无法抢占 CPU,这两种算法分别可能导致后续任务饥饿和长任务饥饿。STCF 在每次有新任务到来时都会评估所有任务的剩余完成时间,从中选择最优任务执行,但耗时很长的任务仍然会因为不能获取 CPU 而饥饿。一个带有合理时间片设置的 RR 能照顾到所有任务,但在周转时间上表现很差,毕竟任务并不能连续的执行完毕,可能需要进行多轮上下文切换。此外,我们可能希望某些任务能尽快完成,而其他任务可以稍微往后放放。MLFQ 在这一点上完成的不错,它预先设置了几个优先级队列,每个优先级的时间片长度不同(优先级越高,时间片越越短)。当一个任务到来时,其优先级初始化为最高,如果是短任务,则很快就会执行完毕,否则逐步降低优先级(当时间片用尽时挪到下一个优先级队列,时间片策略类似于 RR),放到后面执行。比例份额算法的大意是,利用一个份额代表某进程能占据 CPU 的概率,用随机数算法来决定下一个要执行的任务,份额越大,则被执行的可能性越高。另一种步长调度的算法给每个任务分配步长,调度时 OS 选择有最小行程值的任务执行,并将其行程值加上步长值。就像是回合制游戏一样,步长小(速度快)的任务能做到多动,但是步长大的任务也不会饥饿。
多核调度
多核场景下需要考虑缓存一致性和缓存亲和度问题,前者似乎能通过在硬件层面设置监控内存解决,后者则需要多核调度时尽可能将进程保持在同一个 CPU 上。设计调度程序时主要考虑任务队列和 CPU 的交互,分为单队列调度和多队列调度,有点像是 Golang 中的 M 和 P 的交互。
单队列调度相当于 CPU 从一个全局任务队列中消费任务,Golang 的协程调度器最开始也是这样,但是为了提高并发,后面让每个 P 都维持一个局部队列,在 OS 中,单队列的并发访问也同样是性能瓶颈。另外为了保持大部分工作的亲和度,有一部分任务可能不得不由于时间片轮转,在多核之前切换。
多队列调度更像是如今 Golang 的 GMP 模型,每个 CPU 都有一个任务队列,且可以按照不同的调度规则(前面提到的单核调度算法)作业,这样就避免了单队列同步带来的问题,OS 要做的就是决定新来的任务分配到哪个队列之中。为了应对负载不均,常常需要使用迁移策略或者工作窃取机制来平衡各核的工作量(或许 OS 和 Golang 面临的是相同的问题)。
虚拟化内存
地址空间
OS 使用地址空间(address space)的概念来对进程隐藏物理内存的种种细节:

地址空间包含程序的所有内存状态(不要和 PCB 弄混,PCB 包含指向地址空间对应状态的指针),栈用来保存函数调用信息、函数参数、返回值等,堆用来保存动态分配的内存,就像 malloc 做的那样。堆和栈在程序运行中均可以增长或收缩,因此放在地址空间的对侧。地址空间中的内存地址并不等于真实物理地址,OS 在两者之间做了隔离(或者说映射),虽然在进程看来,它拥有从 0 开始的连续内存,但是实际上物理地址并不一致。
分段
如地址空间图所示,典型的地址空间至少包含三个逻辑段(代码、堆、栈),如果我们连同中间未分配的空间一起,在物理内存中给程序分配一段连续内存,可能造成显著的空间浪费,毕竟不是每个程序最终都会塞满未分配空间。更好的做法是类似于懒加载的技术,让程序误以为自己有一大段内存,但是只有在用到某段内存时才进行物理内存分配。这意味着我们可以将三个逻辑段分开放在物理内存中,而不必是像地址空间图中一样整合到一起,对于每个段,MMU 加载它的基址和偏移量即可。
OS 在运行多个程序时,会在它连续的物理内存中为这些程序分配段空间,由此我们又遇到了空闲空间管理的问题,可能空余内存总量能够满足新程序的需求,但是却缺少一段连续的内存能够支撑逻辑段的容量,这就意味着 OS 还需要利用内存分割和合并、碎片整理等机制维持较大的连续空闲内存,还要采取某些策略保证快速内存分配(最好产生的内存碎片也最少)。
分页
分段的长度是不确定的,随着时间推移,内存分配会愈加困难,而分页则是将内存切割成固定大小的单元。相比于分段,需要拿出至少给定段大小的内存,使用了分页策略的 OS 只需要拿出指定数量的页就可以了,不一定非要是连续的。OS 使用页表(page table)记录进程中每个虚拟页在物理内存中的位置,除了反向页表之外,页表都是每个进程独占的数据。我们目前可以把页表理解成简单的哈希结构,其中存放的条目称为页表项(Page Table Entry,PTE)。PTE 的内容包括虚拟页号、物理页号和各种标志位(比如保护位、存在位、脏位等)。
计算机使用地址转换旁路缓冲存储器(translation-lookaside buffer,TLB)来加速地址转换的过程。CPU 在查询页表之前,会优先查看 TLB,如果 TLB 命中,就直接访问映射得到的内存地址,否则更新 TLB(使用随机或者 LRU 策略)。在切换进程时,系统可能需要清空上一个进程留下的 TLB 内容,这将导致新进程出现大量的缓存未命中,有的系统在 TLB 中增加地址空间 ID(ASID),实现进程间的 TLB 共享。
页表的优化
我们仍然假设使用哈希表来实现页表,这意味着页表面临哈希表面临的问题,页表项太多则占据大量内存,而 OS 中每个进程都有一个页表,这就太奢侈了。
一个简单的办法是直接增加页的大小,这样 PTE 的总数就会下降,问题在于大内存页同样导致内存空间的浪费,也许程序只需要在业内使用 1KB,但是页却有 32KB。
段页混合式的方法给每个逻辑段都分配一个页表,这样比较小的栈段和堆段自然拥有更小的页表,而如果给整个地址空间统一分配页表,则页表需要覆盖更大的范围,而地址空间中存在大量未分配的空间,这些虚拟空间本不必占据页表的空间。
多级页表利用索引机制减少 PTE 数目,把连续的 PTE 分割为页大小的单元,如果某一页没有任何 PTE,则不分配实际页表。查询时则需要首先查询目标 PTE 所在的位置,再到对应的页中查询。
还有一种反向页表(inverted page table),用物理页做键,虚拟页和进程做值,如果要寻找某一虚拟页对应的物理页,则需要全表扫描,但由于物理页的数目是确定的,这种办法在牺牲效率的同时提高了空间的利用。
Swap 机制
OS 通过增加交换空间来为并发运行的进程提供较大的地址空间(当然只是假象),也即,在硬盘上开辟一部分空间用于物理页数据的转存。当内存不足时可将一部分内存数据交换到这部分区域中,当需要使用这部分数据时,再将数据交换回来。
我们使用平均内存访问时间(Average Memory Access Time,AMAT)来衡量硬件缓存:
其中,
并发
线程
线程类似于进程,但它们共享地址空间,从而可以访问相同的数据,是 CPU 调度的最小单位。每个线程都有自己独立的栈,想象一下在地址空间中,原本未分配的空间中分布着多个栈。
锁的实现
在硬件层面支持下面几种原语,以支持锁,其关键是这些代码都会原子地执行。
Test and Set
int TestAndSet(int *old_ptr, int new) {
int old = *old_ptr;
*old_ptr = new;
return old;
}Caompare and Swap
int CompareAndSwap(int *ptr, int expected, int new) {
int actual = *ptr;
if (actual == expected)
*ptr = new;
return actual;
}Fetch and Add
int FetchAndAdd(int *ptr) {
int old = *ptr;
*ptr = old + 1;
return old;
}信号量
信号量是一个有整数值的对象,可以进行 P 操作(如果信号量非负的话,否则等待)和 V 操作,前者将信号量减一,后者加一。信号量可以用作锁、条件变量等。
读者 —— 写者锁
哲学家就餐问题
死锁条件
- 互斥:线程对于需要的资源进行互斥的访问。
- 持有并等待:线程池有了资源,同时又在等待其他资源。
- 非抢占:线程获得的资源,不能被抢占。
- 循环等待:线程之间存在一个环路,其中每个线程都额外持有一个资源,该资源又被环路中的下一个资源需要。
持久性
磁盘
磁盘的 IO 时间可分为三个部分:寻道、旋转和传输,由于物理设计上的限制,时间主要花费在前两个阶段。这就要求 OS 采取策略尽量减少寻道和旋转上花费的时间,由此有了磁盘调度算法:
- 最短寻道时间优先(Shortest Seek Time First,SSTF):每次选择最近的磁道完成请求。
- SCAN:以跨越磁道的顺序来服务磁盘请求。
- 最短定位时间优先(Shortest Positioning Time First,SPTF):视寻道和旋转的情况决定下一个服务的请求。
文件系统
文件系统可以说是计算机持久化数据行为的虚拟化,一般而言,一个文件系统在磁盘上的数据组织包括:
- 超级块:包含关于特定文件系统的信息。
- inode 表:集中存放 inode,用于保存文件的元数据(长度、权限、块的位置等)。
- 数据区域。