简易KV存储服务构建
6.5840 / 6.824(分布式系统)Lab 3,基于Raft算法实现一个可容错的KV存储服务。
NOTE:本文为 6.824(分布式系统)Lab 3 的回顾,实验要求见这里。因为要遵守课程的 Collaboration Policy,所以本文不会分享任何实现细节的代码(可能还是会有一些逻辑性的简单代码帮助阐明思路)。
在 Lab 3 中,我们基于之前 Lab 2 实现的 Raft 协议构建一个 KV 存储服务,此外还提供基础的快照功能,确保系统的可容错性。在某种意义上,可以认为这是一个简陋的 Redis,去掉了高效的数据结构和 IO 上的优化,性能上也完全说不过去,但用来加强对 Raft 的理解倒是很有用。
服务架构
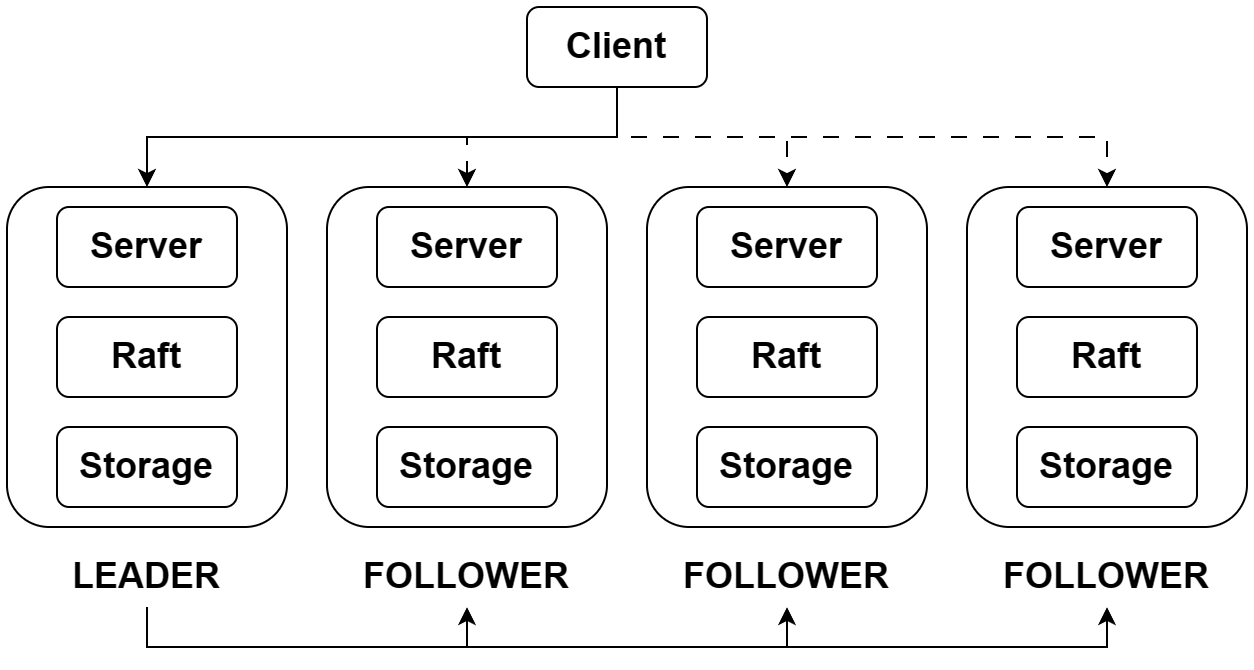
整体而言,整个结构分为客户、服务、Raft 和物理存储四层:
- 客户层即直接面向应用的 KV 数据库,向外暴露 Put、Append 和 Get 三种接口。客户层可以直接和下层 Raft 服务集群通信,但只会向集群 LEADER 发送请求。
- 在服务器中,KV 数据是直接存储在内存中的,Lab 中直接使用了 Golang 的
map,但这显然是一种简化处理,实际项目中要对内存利用做更多优化(脑子里不禁又开始联想 Redis)。 - Raft 层确保了集群各成员之间的强一致性,这部分在 Lab 2 中已经实现。放在 KV 存储的应用场景中,上层的服务将 log 信息传递给 Raft,Raft 在确保 log 同步到集群多数之后,向服务层传递信息,此时服务层可将操作应用到状态机中。
- 物理存储层即 Lab 2 中用到的 persister,负责持久化 log 和服务器的状态,这样服务器遇到故障重启后不至于落后整个集群状态太远。
三种基本操作的实现
对于每个客户请求,Client 实际上是将请求封装到 RPC 参数中,传递到服务层存储并等待服务层返回 RPC reply。在此过程中,Client 需要遍历集群,访问集群成员状态,直到找到 LEADER,后面可以直接将 LEADER 保存在 Client 缓存中,下次访问直接从 LEADER 开始。另外,我们需要记录 Client 访问 Server 时发出的操作请求的顺序,服务器必须按序处理请求过程,这里我直接使用了一个自 0 开始的序列号作为标记。为了应对多个 Client 并发操作的情况,我们还应该给每个 Client 一个特殊标识,在实际的应用中这意味着采用一种分布式 Id 生成方案(日后我会总结一下),但是在 Lab 中,直接使用随机数也没啥问题,test 代码的用户数量很少,显然是希望把注意力集中在 KV 存储这一块。
server 在接收到 Client 的 RPC 请求后,会将对应的操作封装起来传递给下层 Raft,等待操作被 apply,在那之后返回操作结果。操作从提交到 Raft,到 Raft 通过 applyCh 返回,是一个异步过程。server 中有一个独立线程持续消费 applyCh 中的内容,每当获取一个操作,首先判断操作是否是顺序操作,要是是乱序,那么可以丢弃,然后再根据操作类型对内存中的数据进行处理。
总结起来看:
- Client 需要提供
clientId、requestId和操作参数(对 Get 来说是键,对 PutAppend 来说还有值)。 - Server 需要保存当前的操作序列(由
clientId和requestId标识),和下层 Raft 通信,并在内存中维护一个 map,以存储键值对数据。
server 的响应过程
从上面的分析可以看出,client 相对轻量化,重要的工作都在 server 上,因此我们下面重点关注一下 server 对操作的处理。
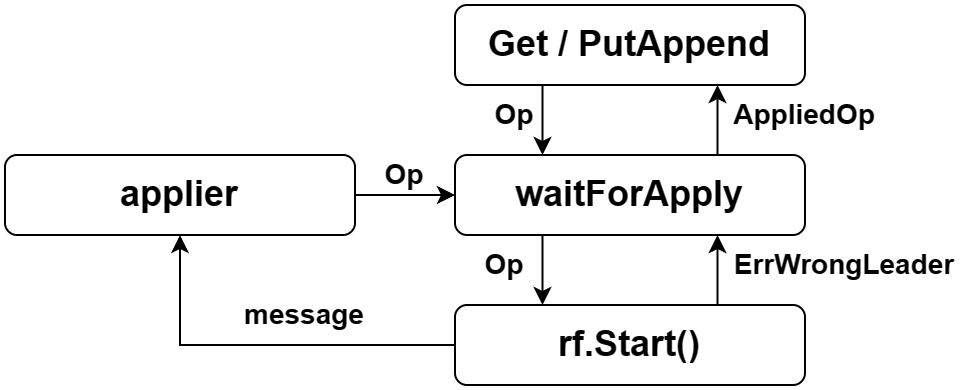
首先 server 收到 client 的 RPC 请求,将操作(所有需要 Raft 来同步的数据)封装到一个 Op 中,这个结构体代表一个数据库操作。
type Op struct {
Key string
Value string
RequestId int64
ClientId int64
Type string
}紧接着,server 调用 waitForApply 函数,其中会调用 Lab 2 暴露的 rf.Start() 函数,如果不是 LEADER,Start 会直接返回相关信息,server 也就可以直接返回一个 ErrWrongLeader 错误。反之,LEADER 会返回这个 Op 对应的 log 的索引值(回顾一下 Lab 2,LEADER 在复制 log 之前,会给客户,也就是这里的 server,返回一个计划索引值)。我们在 server 中临时创建一个 channel,用于接收返回的消息。
与此同时,server 的 applier 协程一直在消费来自 Raft 层 applyCh 的内容,那么在正常情况下,它必然最终能够接收到 Op 对应的 Applied Message。如果这条 message 是操作信息,那么我们提取出其中的 Command,转换为 Op(事实上 Command 是一个 interface),对比并更新 Client 的操作序列号(这在前一节提到了),如果是顺序数据,就按照要求对 KV map 进行更新,然后将更新结果写入 Op 中,传入前面的 channel(如果该 channel 存在)里。
最后,我们在 waitForApply 中监听这个 channel,如果超时就返回 ErrTimeout,提示 client 重试,反之,对比返回的 Op 和原 Op 的标识信息,如果相同,则说明这就是我们请求对应的返回,将这个结果返回给 client,否则说明 Raft 层内部可能由于网络或者主机崩溃等原因,LEADER 发生了改变,或者消息同步不及时,返回报错,让 client 重发请求。
快照功能实现
我们在 Lab 2 中实现了 Raft 算法的数据持久化,分为两个部分:
- log compaction:一旦内存中的 log 超出一定数量,我们就将之前的 log 裁剪,利用 persister 将之保存起来。
- server 层状态持久化:Raft 层响应 server 层的 Snapshot 请求,将 server 层序列化的数据持久化。
因此,我们这里只需要 server 层采取一定策略序列化服务器状态,在启动服务器时读取快照即可。
存储的数据主要是当前内存中的 map,否则崩溃之后数据丢失,还得对 log 做 replay(again,想到 RDB 和 AOF),以及对各个 client 的历史序列号的记录。
我采取的策略是在 applier 中检查 Raft 层的 log 长度,一旦超过 server 层的限制,马上保存一次快照。