从0开始实现一个简单的MapReduce
6.5840 / 6.824(分布式系统)Lab 1,实现一个简单的MapReduce系统。
NOTE:本文为 6.824(分布式系统)Lab 1 的回顾,实验要求见这里。因为要遵守课程的 Collaboration Policy,所以本文不会分享任何实现细节的代码。
MapReduce 架构
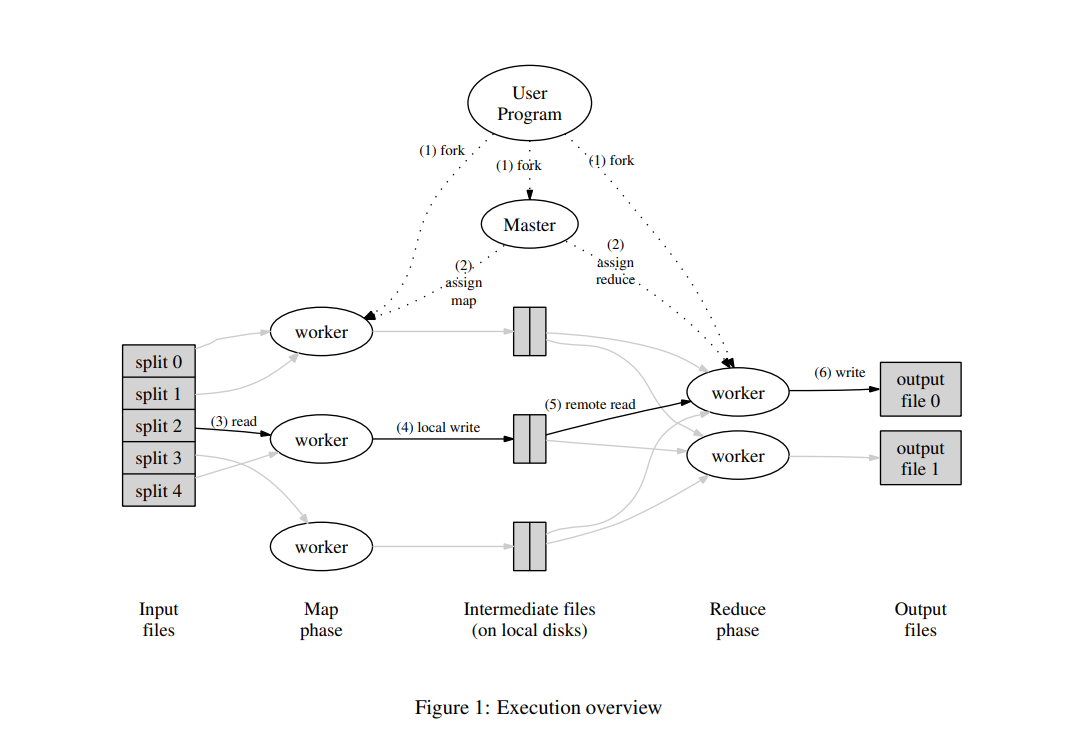
原论文对 MapReduce 架构的描述已经很清晰了。想象一下你有一个复杂的任务,或者你有很庞大的数据要计算,但是实验室的计算机配置不够。比起说服老板升级机器,更可行的方案是把任务分解成若干单机可以承担的子任务,交给单机并行计算,最后再在某一台机器上汇总结果。这就是 MapReduce 的基本思想。
MapReduce 把这种并行分布计算的过程分为 Map 和 Reduce 两个阶段:
- Map 阶段:把输入的原始数据分解成若干个子任务,交给多台机器并行计算,每台机器都会输出一个中间结果。
- Reduce 阶段:把 Map 阶段输出的中间结果汇总,得到最终结果。
以计算一本书中每个单词出现的次数为例,MapReduce 的过程如下:
首先将书籍分为若干数据块,每个数据块交给一台机器进行 Map 操作,即每次看到一个单词,就输出一个键值对 (word, 1),即代表看见了一个单词 word。这样每台机器都会输出一个中间结果,即它所负责的数据块中的单词出现的情况。
接着会由某台或某些机器(如果多于 1 台,则最后会输出多个文件)把中间结果作为输入进行 Reduce 操作,即对于每个单词,把它的所有出现次数相加,得到最终结果。
为了实现这样的分布式计算系统,我们需要这样两种角色:
- Master:(在 Lab 中称为 Coordinator)负责调度任务,分配任务(Map 和 Reduce 任务)给 Worker,收集 Worker 的中间结果,最后汇总结果。
- Worker:(在 Lab 中称为 Worker)负责执行任务,执行 Map 和 Reduce 任务。
系统中只有一个 Master,但 Worker 数量不限。Master 与多台 Worker 之间通过 RPC 通信。
计算流程
在设计中,用户会提供 Map 函数、Reduce 函数和输入文件(在 Lab 中两个函数以插件形式提供)给 MapReduce。而后 Master 会根据输入文件的大小或者数量,将原始文件切分为若干个数据块,作为 Map 阶段的输入(Lab 中一次会输入多个文件,这些文件自动作为多个 Map 任务的输入,这实际上简化了问题)。
Worker 将持续不断地向 Master 请求任务,而 Master 会根据目前所有任务的完成情况,将某个任务分配给 Worker。Worker 执行完任务后,会向 Master 汇报任务的完成情况,以便 Master 实时更新全局任务的完成情况。
Master 会将全局任务分为 Map、Reduce 和 Done 三种状态。最开始系统处于 Map 状态,当 Master 检测到所有 Map 任务都已完成,则切换到 Reduce 状态,向 Worker 分配 Reduce 任务。Reduce 任务均已完成后,Master 切换到 Done 状态。在此期间,用户会轮询任务的完成情况(Lab 中每秒检测一次),当检测到 Master 状态为 Done,就可以得到计算的最终输出结果。
Master
在 Lab 中,Master 的关键函数有四个:
Coordinator():Master 的入口函数,负责初始化 Master 的状态,包括任务队列,全局任务状态,Reduce 任务的数目等。AssignTask():检查任务队列,分配任务给 Worker,为已分配的任务设置超时时间。RecollectTask():一个单独的线程,每隔一段时间检查已分配任务的超时状态,如果发现任务超时,则说明 Worker 或者网络出现故障,该任务可以被重新分配给其它 Worker。Transit():每当有任务完成时,检查任务队列,如果发现所有任务都已完成,则切换到下一个状态。
我在 Master 中使用了一个切片存储待分配队列,用一个 map 存储当前阶段所有已分配任务的状态。
- 当有 Worker 请求任务,则查看待分配队列,如果不为空,则分配任务给 Worker,并将该任务放入 map,否则返回空任务。
- 当有 Worker 返回处理结果,则会更新任务状态,并将其从 map 中删除,如果发现所有任务都已完成,则切换到下一个状态。
- 在 Master 初始化时,开启另一个线程定时检查 map 中的任务是否超时,如果超时,将该任务重新放入待分配队列。
为了应对多个 Worker 同时请求任务的情况,Master 中访问任务队列和任务状态的操作都加了锁。
Task:连接 Master 和 Worker
重新想象一下 Master 和 Worker 的通信过程:
- Worker 向 Master 请求任务。
- Worker 执行完任务后,告知 Master 执行情况。
这两个过程中,Task 实际上充当了通信的桥梁,它至少应该包含如下信息:
- 任务的类型(Map 或 Reduce):Worker 根据不同的任务类型调用不同的函数。
- 任务的输入文件名:Worker 根据输入文件名读取输入文件。
- 任务的编号:Worker 执行完任务后,需要告知 Master 任务的编号,以便 Master 更新任务状态。
Worker
Worker 从用户输入中获取 Map 和 Reduce 函数(以插件形式)。
Worker 自初始化后,将持续不断地向 Master 请求任务,直到 Master 切换到 Done 状态,并根据任务的不同类型,调用不同的函数进行任务处理。
需要注意一点,Worker 在执行任务时总会生成一个临时文件,用于储存中间结果,只有 Master 确认该任务已经完成,才会把临时文件名修改为正式的输出文件名,这是为了避免 Worker 在执行任务过程中出现故障,导致 Master 误认为该任务已完成。
一些问题
- 任务输出文件的最终命名始终由 Master 决定,Worker 只需要将中间结果写入临时文件即可。
- 任务的超时时间应该如何设置?如果设置过短,会导致任务频繁重新分配,影响系统性能;如果设置过长,会导致任务完成后,Master 无法及时更新任务状态,影响系统的实时性。
- 需要注意 Master 在分配和更新任务时需要加锁,防止并发访问造成冲突。
此外,Lab 中的 MapReduce 实际上运行在一个相当理想化的网络环境中(单机环境中的 IPC),而在真实情况下,还需要考虑异地容灾、网络延迟、网络抖动等问题,而这需要额外设计来保证系统的可靠性和实时性。