Git数据模型一窥
当我们在使用Git的时候,我们究竟在做什么?
之前我对 Git 的印象仅限于一个简单的版本管理工具,VS Code 之类的开发工具会将常用的 Git 命令封装到 UI 界面上。彼时的我也就只是简单地接触了 commit、add、push 之类的封装好的操作,当遇到需要版本回滚或者冲突合并的时候,很可能就会傻眼,以删除.git 文件夹结局。我在机缘巧合的时候看了 The Missing Semester of Your CS Education 中 Version Control 的一课,讲师用结构体的方式描述了 Git 的数据模型,给我留下了很深印象。正好最近也重翻了 Pro Git,以本文记录一下自己对 Git 数据模型和常用命令的理解。
工作目录、暂存区和仓库
Git 中的文件可分为三种状态:
- 已修改(modified):文件已经被修改,但还未提交到暂存区。
- 已暂存(staged):文件已经被修改并提交到暂存区,但还未提交到仓库。
- 已提交(committed):文件已经被提交到仓库。
以此,我们可以将 Git 的工作流程简单描述为:
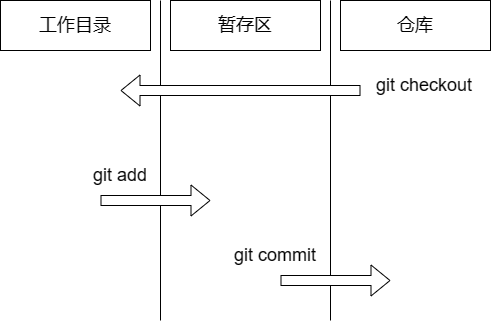
仓库即 .git 文件夹,其中包含了 Git 的所有数据,包括版本库、暂存区、分支信息等。我们可以通过 git init 命令将一个文件夹初始化为 Git 仓库,或者通过 git clone 命令克隆一个远程仓库到本地。
暂存区即 index ,是一个二进制文件,记录了下一次提交的文件列表和文件快照。我们可以通过 git add 命令将文件添加到暂存区,或者通过 git rm 命令将文件从暂存区移除。
工作目录是项目版本的 checkout(从仓库中检出),即我们当前所处的工作目录。我们可以通过 git checkout 命令将工作目录切换到某个分支或者某个 commit。
在通常的 Git 工作流程中,我们会修改工作目录中的文件,将之加入暂存区,然后将暂存区中的文件提交到仓库。
Git 数据模型
Git 对象
Git 将整个项目分为两种对象: blob 和 tree 。 blob 即文件快照,可简单视作连续存储的字节, tree 即文件夹快照,其中可包含新的文件夹或者文件。而一个 commit 则是整个项目的快照,因此包含了一个 tree 对象,此外,还将包含父 commit 、作者、commit message 等信息。
此外,Git 中还有 object 的概念,前面的三种对象其实都是 object 。在某种程度上,Git 可以被视为一个键值对数据库,其中的键为 object 的 SHA-1 哈希值(这在计算机网络或其他领域被广泛用来进行内容校验),值为 object 的内容。
我们用 Go 语言的结构体来描述上述内容(当然,实际上的 Git 对象模型要复杂的多,这里只是简单反应对象之间的关系):
var objects map[string]object // key: hash, value: object
func store(object object) {
hash := sha1(object)
objects[hash] = object
}
func load(hash string) object {
return objects[hash]
}
type object interface {
hash string
}
type blob struct {
object
content []byte
}
type tree struct {
object
entries map[string]string // key: filename, value: hash of blob or tree
}
type commit struct {
object
tree string // hash of tree object
parents []string // hash of parent commit
author string
message string
}可见, object 用 hash 值来索引(而非直接存储其他的 object ),其用法类似于指针。
commit history
我们可以用 git log --oneline --decorate --graph --all 可视化一个 Git 仓库的 commit history(当然一些软件也有更漂亮的可视化界面,但命令行无疑更通用),可以看到,所有的 commit 在事实上组成了一个有向无环图(directed acyclic graph, DAG)。
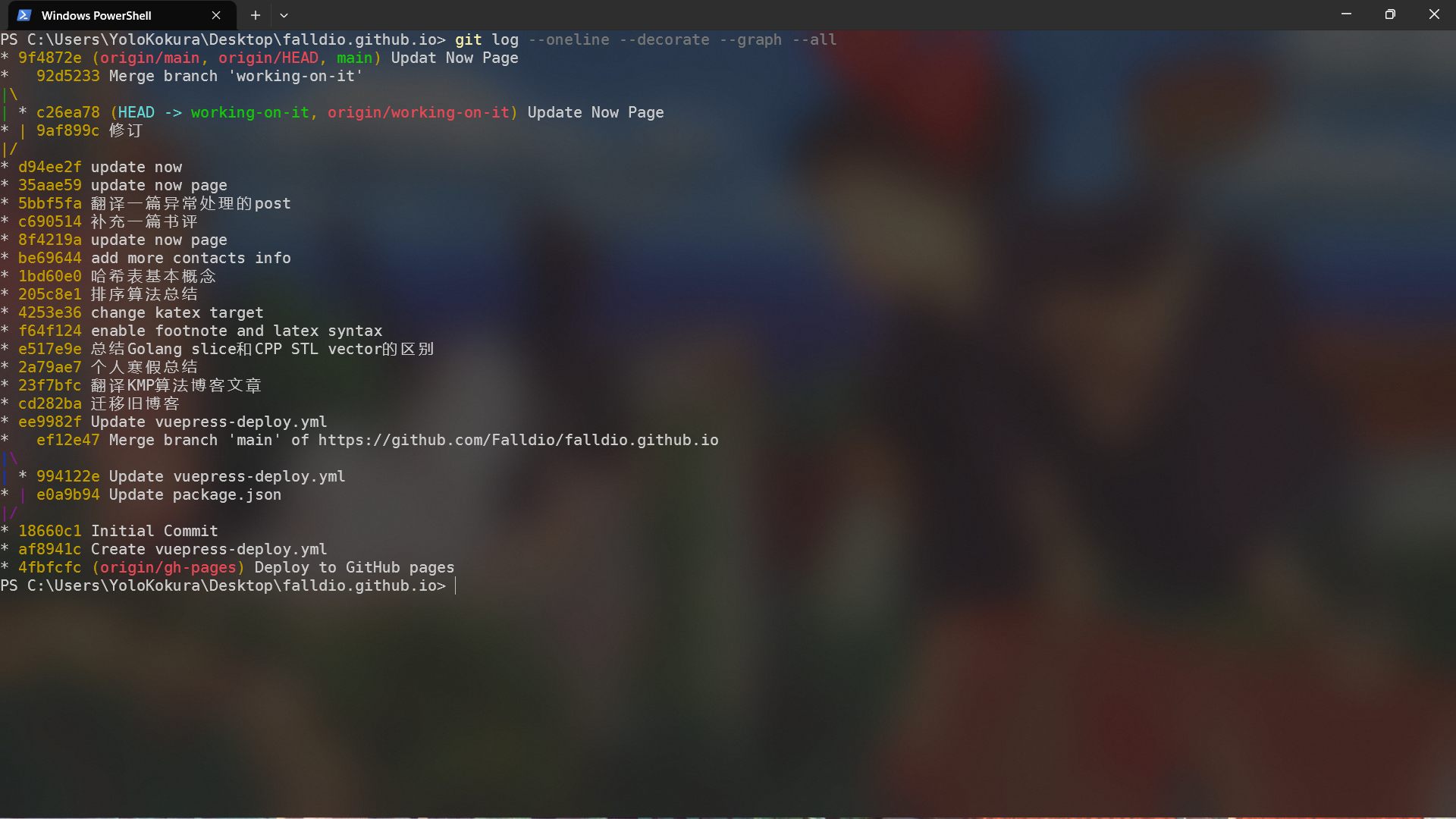
图中第一列视作 DAG 的结构,第二列为 commit 的 hash 值(前几位),第三列若有括号,则代表括号内的分支(本地或者远程)的 HEAD 指针指向该 commit,第四列为 commit message。
让我们更深入的看一下 object 之间的关系,我们注意到图中 排序算法总结 这个 commit 的 hash 为 205c8e1,我们可以用 git cat-file -p 205c8e1 查看该 commit 的内容:

可见该 commit 包含 tree、parent、author、committer、commit message 等信息,同我们前面提到的结构基本一致。如果我们用类似的命令查看 tree 对象,可以看到:

可见,这个 commit 包含的 tree 对象实际上是整个项目的快照,其中既有嵌套的 tree ,也有文件 blob 。我们不妨更进一步,查看其中的 blob 对象,以 package.json 为例:
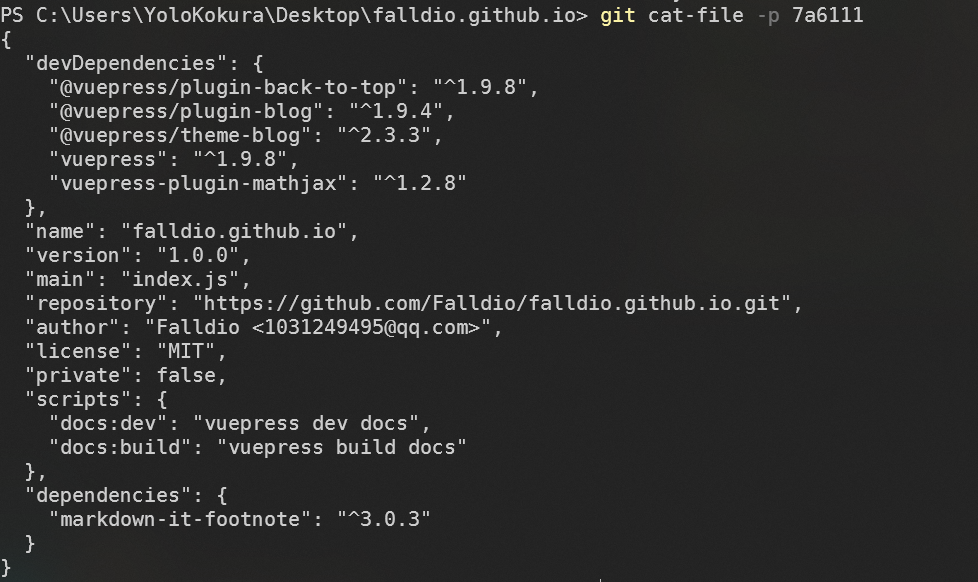
显而易见我们得到了该 blob 对象的内容。
指针与分支机制
移动指针
当我们有了这样一个 DAG 结构后,我们做的一系列操作实际上就变成了在 DAG 上移动指针或者修改图结构的过程。Git 中的指针指向的是 commit,例如上图中,我们看到的 HEAD -> working-on-it 即代表本地的 working-on-it 分支的 HEAD 指针指向该 commit,而 origin/working-on-it 即代表远程的 working-on-it 分支的 HEAD 指针指向该 commit。HEAD 指针代表的是我们目前所在的 commit 。
我们当然也可以直接使用 commit 对象的 hash 值来快速移动,如 git checkout 205c8e1 :
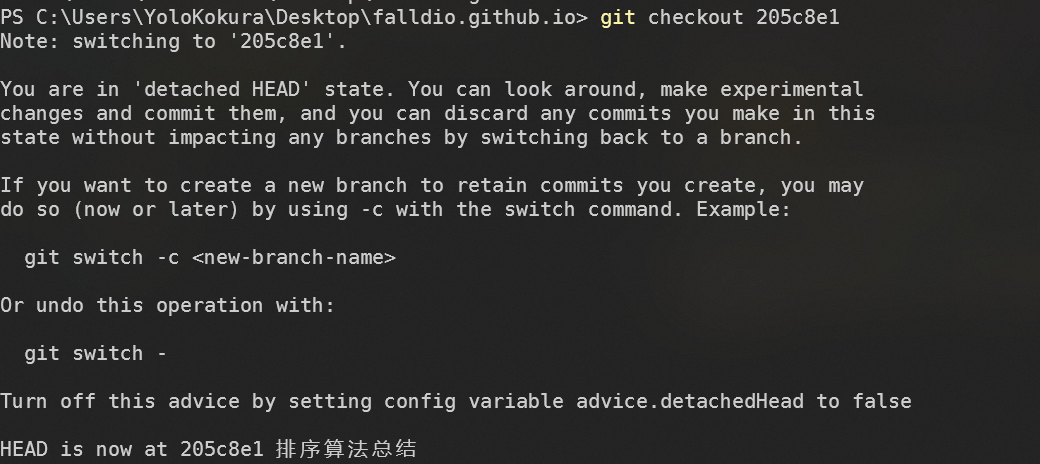
此时我们再用 git log 查看指针状态,可见:
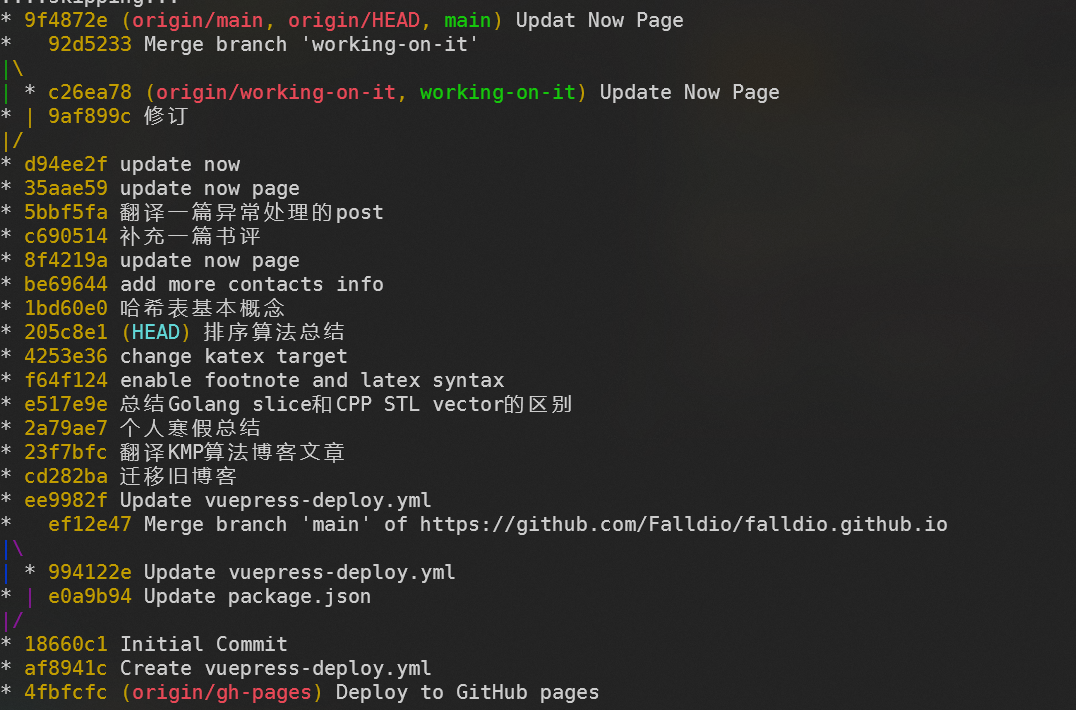
HEAD 指针指向了 排序算法总结 这个 commit,而 working-on-it 分支仍然指向之前的位置。由此可见,HEAD 总是代表我们当前所在的位置(默认状态下也会随着文件的修改向前移动,除非和我们一样强行 checkout 到一个新的 commit ),而分支名所代表的指针指向该分支的最新 commit。利用 hash 值来移动指针的好处是,我们可以更加灵活地在 DAG 上移动,而带有语义的分支指针则方便我们理解 where we are。
本地分支
既然分支本质上就是指向 DAG 结点(即 commit 对象)的指针,本地分支之间的切换,其实也就是把 HEAD 指针指向不同的分支指针而已。例如,我们可以用 git checkout -b new-branch 来创建一个新的分支,此时 HEAD 指针指向了新的分支指针,而新的分支指针指向了 HEAD 指针之前所指向的 commit,即:
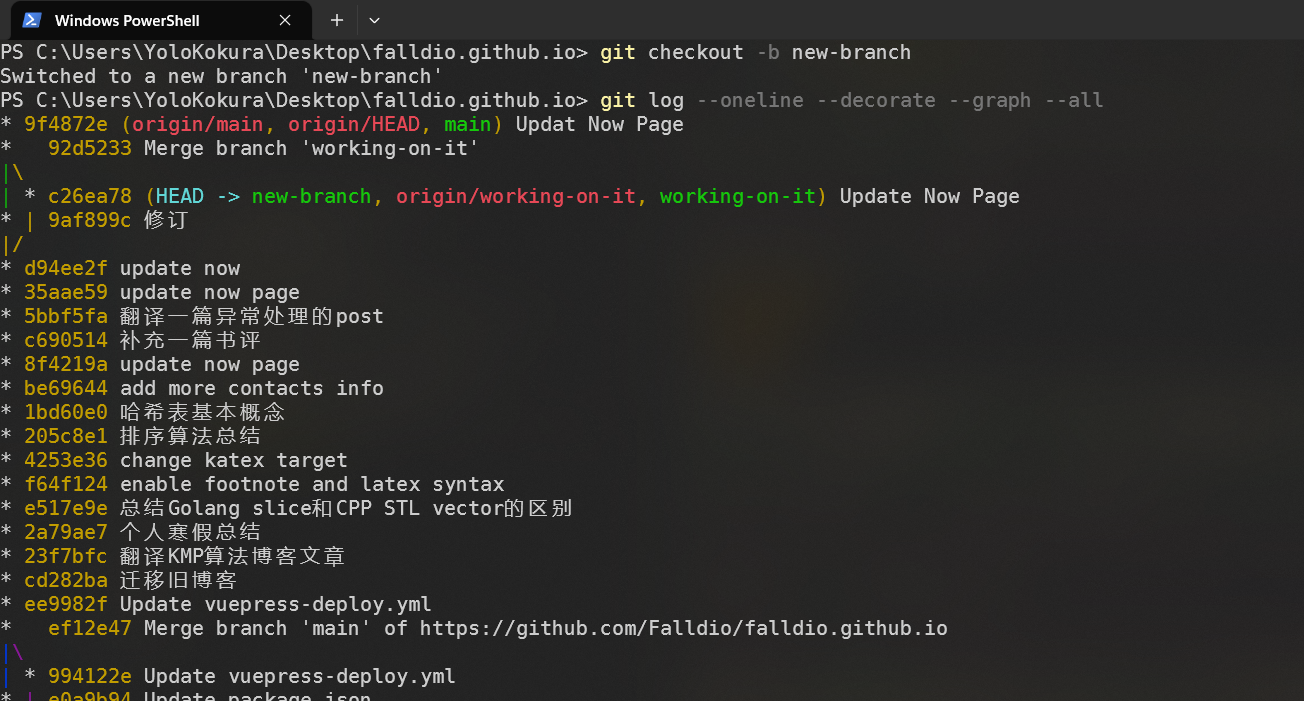
分支使得我们可以同时在不同的 commit 上进行工作,而不会相互影响。例如,我们可以在 main 分支上进行一些 bug 修复,而在 working-on-it 分支上进行新功能的开发,而不会相互影响。当我们在 working-on-it 分支上完成了新功能的开发后,我们可以将其合并到 main 分支上,这样就完成了新功能的开发。
当我们需要将分支合并时,则只需要切换到目标分支(即被合并到的分支),使用 git merge 即可。例如,如果要把 working-on-it 分支合并到 main 分支,则只需要切换到 main 分支,然后使用 git merge working-on-it 即可。
合并时,Git 会自动找到两个分支的最近的共同祖先,然后将两个分支的修改合并到一起,如果没有冲突,则会自动完成合并,否则需要手动解决冲突,然后再次提交。这在 DAG 上体现为两个树枝被合并到同一个新的子结点。
远程分支
BTW,Pro Git 的 3.4 节介绍了常用的与分支有关的工作流,可以参考。
远程分支实际上也是 DAG 上的指针而已,只不过它所在的 DAG 在远程仓库上,由于多人合作等原因,这个 DAG 和本地 DAG 并不能时刻保持一致,需要我们通过 fetch、pull 和 push 等操作来保持同步。
我们本地保存的实际上是上一次同步时,远程分支在 DAG 上的位置,而不是远程分支的最新位置。当我们使用 git clone 克隆一个远程仓库时,Git 会自动创建一个名为 origin 的远程服务器,它所指代的是该远程仓库的 url,这和用 branch 名指代 hash 值异曲同工。而远程分支则是以 origin/branch-name 的形式存在的,例如 origin/working-on-it 。
当我们使用 git fetch 时,Git 会自动将远程仓库的最新状态下载到本地,此时 origin/working-on-it 指针会指向远程仓库的最新状态,但此时本地的 working-on-it 分支仍然指向当前工作的位置。如果我们此时使用 git merge origin/working-on-it ,则会将远程仓库的最新状态合并到本地的 working-on-it 分支上,此时本地的 working-on-it 分支指针会指向远程仓库的最新状态,而 origin/working-on-it 指针则不会改变。
比 git fetch 更常见的 git pull 操作,实际上就是 git fetch 和 git merge 的组合(有一种语法糖的感觉),即先将远程仓库的最新状态下载到本地,然后再将其合并到本地分支上。 git push 与之相反,它会先 fetch 、 merge ,然后再将本地的最新状态推送到远程仓库,从而修改远程分支的位置。
在执行 git push 时,我们往往是将本地分支的进展推送到一个对应的远程分支上,因此我们需要为本地分支设置追踪分支(tracking branch 或 upstream branch),能实现类似效果的方法有下面几种:
# creare a new branch and set upstream branch
git checkout -b new-branch origin/branch-name
git checkout --track origin/branch-name
# change or set upstream branch of current branch
git branch --set-upstream-to=origin/branch-name
git branch -u origin/branch-namegit rebase
git rebase 也是一种整合分支的手段,它是将一个分支上的修改以补丁的方式应用到目标分支上,类似于 Redis 的 AOF 持久化模式,将数据库操作记录下来,恢复数据库状态时,只需要将操作记录重新执行一遍即可。从 DAG 的角度来看,rebase 命令实际上删改了一些节点,在图结构上,就好像是目标分支一路修改过来一样,另一个分支就像是从来没存在过一样。
这样做可以给我们带来更加简洁的 commit history,毕竟图结构变得更线性,不再乱糟糟的,但它仍然存在弊端:如果对已经存在于远程仓库上的 commit 进行 rebase 操作,修改了远程的 DAG 结构,那么远程 DAG 和其他合作者的本地 DAG 结构将存在冲突,他们必须重新将自己的工作整合到新的 DAG 结构上,然后我们再 pull 他们的成果,这样就会造成很大的麻烦。
借用 Pro Git 的一句话:
Do not rebase commits that exist outside your repository and that people may have based work on.